What is Pulumi - why should you take a look at it? Learn from my deep dive into Pulumi, I compare it against Terraform and try to explain why I predict this approach will take hold and become the next prominent form of IaC.
What’s Pulumi?
Pulumi is “Infrastructure as Code”, using - you guessed it - real code.
In Pulumi you use Typescript/Javascript, Go, .Net Core (C#/F#) or Python to describe your infrastructure.
Using code has some really interesting benefits, some are obvious such as the ability to control conditional logic and loops more easily than with Terraform, some are less obvious but nonetheless extremely powerful.
I won’t cover the basics of IaC here, that is something google can help you with.
Back story / goals
I recently performed a deep dive into Pulumi to see how it can be used to build production-like infrastructure (in Azure). This is part of my work for soxes GmbH , a software company in Switzerland.
Roughly in this order, I set out to find answers to:
- what (unexpected) benefits does IaC via code provide?
- what is the experience like? is Pulumi easy to learn/use?
- what is the community like? how vibrant is it?
- is there great documentation, samples and learning material?
- are there any gotchas?
- pricing / operational risk?
- how does it compare to Terraform?
Related to the devops work I’m doing for soxes, I also wanted to know how Pulumi might help:
- “Shift stuff left” - reducing the time to build and deploy because devs can build the infrastructure instantly, get feedback, change it as required, and so on - enabling a much faster feedback loop for development
- Wrap complexity - clouds are complex, can we make it easier for developers to just be developers, instead of them having to worry (or even see) whether the system nodes of the AKS cluster need to be in a separate subnet - this is an area where I think Pulumi excels
- Make it easy to refactor infrastructure - this is where Pulumi’s idea of Input/Output and their Pulumi Service play a big role
- Break down the dev & ops barrier a little bit - and dear to my heart: make the experience more enjoyable - when the dev lifecycle is easy it’s possible to get more flow
Easy.
That’s not too much of an ask is it?
Thank you Terraform
I’m not saying that Terraform is bad, or that it is unenjoyable, or that it sprouts small manic goblins (or worse, as I’ve been reliably informed, a Balrog) that jump out from nowhere to bash the poor dev or ops fingers with tiny wee hammers. I’m not even sure if a Balrog can even hold a hammer, wouldn’t the hammer just burn up and melt?
No. I digress.
Terraform is a fantastic tool and its powering some amazing infrastructure pipelines around the world - which of course I’ve not personally seen but I’m going to run with this statement since it’s the de-facto standard tool for IaC these days.
Google Trends backs me up too - and had this to say about Terraform, Pulumi and Cloud Formation:

The problem
I’ve used Terraform for a few years - it’s really good and I’m happy with the results.
As a developer, Terraform is definitely additional cognitive load and complexity on top of an already extremely complex job - so while Terraform is great, I’m on the lookout to find ways to make it easier for developer teams to integrate operations work into their daily flow.
Terraform deploys infrastructure by using a “desired state” model, written in Hashicorp Control Language.
While the desired state model is a solid idea, HCL has some limitations, a few of which are: looping, branching, encapsulation and sharing (both module and at a higher level).
This isn’t the article to explain Terraform - the main take away I want to provide is that HCL isn’t a language that can be used to express complex logic.
Pulumi uses code, so complex logic is what it eats for breakfast.
The approach and scope
I learn better by doing.
The idea was to use Pulumi to deploy a (small) working development environment.
The choice of technology is driven by critical parts of my client’s new development structure. The example environment is real enough to get a feel for how Pulumi works - we decided to deploy:
- A Kubernetes Cluster
- A Container Registry
- The required Service Principals and Roles that allow the Cluster to pull from the Registry, as well as a developer workstation to push images to it
- DAPR runtime into the Cluster via the official HELM chart
- The build of images on a “dev” workstation
- Pushing the images up to the container registry
- And finally, dapr-traffic-control - this fictitious traffic control service is used to teach DAPR and is a great way to test the tooling. It uses building blocks, deploys 4 apps and is ready to go
I’m using Azure in this case - the same conclusions apply to other cloud providers.
The experience
Pulumi is entirely new to me - so I spent time up front to understand the basics.
I spent just under 4 days in total on this project, this includes learning, experimenting, building, reflecting, asking questions and summarizing. I feel like I spent almost a whole day reading the Pulumi docs, and about 3 hours on the Pluralsight course.
Structure
I built two Pulumi Projects , one for the infrastructure, that is the cluster itself, a container registry, DAPR and other bits and pieces - and one project for the application, which includes docker based builds, push & deployment steps.
Both projects contain a single stack.
I feel it’s important to mention that nobody told me to “do it this way” - and my technique does not represent an official best practise. It was mostly just because I wanted to experiment with the StackReference class and to me there is a natural separation between the underlying cluster and what gets installed into/on it.
Warnings, waivers and small print out the way - lets move on.
A StackReference makes it possible to refer to a deployed stack in any organization/project. I used it in the application project to refer to the infrastructure project - so I could get hold of the cluster connection information.
This meant that my application project would automatically install its workload(s) into the appropriate cluster, with no further configuration from the developer being required.
Gotcha!
While the StackReference is a good idea, and I will continue to use it - it can lead to a problem. This problem is likely going to manifest mostly during development scenarios, and almost never in a real CI/CD pipeline.
The root of the issue is that the Pulumi Service doesn’t know that the application project depends on the infrastructure project.
If I were to delete the infrastructure project, the entire cluster gets deleted - this is fine and expected.
Where it gets hairy is the state stored in the Pulumi Service for the application project - the Pulumi Service has no link or reference between the infrastructure and application projects and thus the Pulumi Service still assumes the application resources exist.
In my example above where I delete the infrastructure project, those resources definitely do not exist, as the cluster, along with everything else within it, is now just a fleeting memory.
Given the cluster is no longer around, if I tried to do something like pulumi preview; the CLI command just times out and throws an exception. Go on, ask me how I know.
Maybe it’s useful for you - the stack trace contained the following:
at Task<int> Pulumi.Deployment+Runner.RunAsync<TStack>(Func<TStack> stackFactory)
---> System.Collections.Generic.KeyNotFoundException: Required output 'registryUrl'
does not exist on stack 'effectiveflow/traffic-app/basic'.
This is because the application project has a reference to the registryUrl stack output of the infrastructure project - and the reference cannot be resolved of course.
To solve this is actually trivial; either you remember to delete projects in the right order and there is no problem, or you need to gently force the Pulumi Service to catch up to reality.
To force delete the stack state (via Pulumi CLI), do this:
pulumi stack rm --force --preserve-config
Remember to use the --preserve-config flag, so that your local stack configuration file isn’t
deleted along with the underlying state data from the Pulumi Service. Go on, ask me how I know that one too.
The Eureka moment
There was a “light bulb / Eureka” moment too… where it became crystal clear that because of the general purpose language that made re-use of existing tooling - something new is possible: I can now create versioned infrastructure libraries that are much easier to use and consume.
It’s hard to overstate how important this is. Because I can design the code in any way I want, I can expose arbitrarily complex infrastructure in just one, or a few lines of code.
This in turn fuels the ability to share local experiences globally throughout an organization.
Encapsulation of complexity
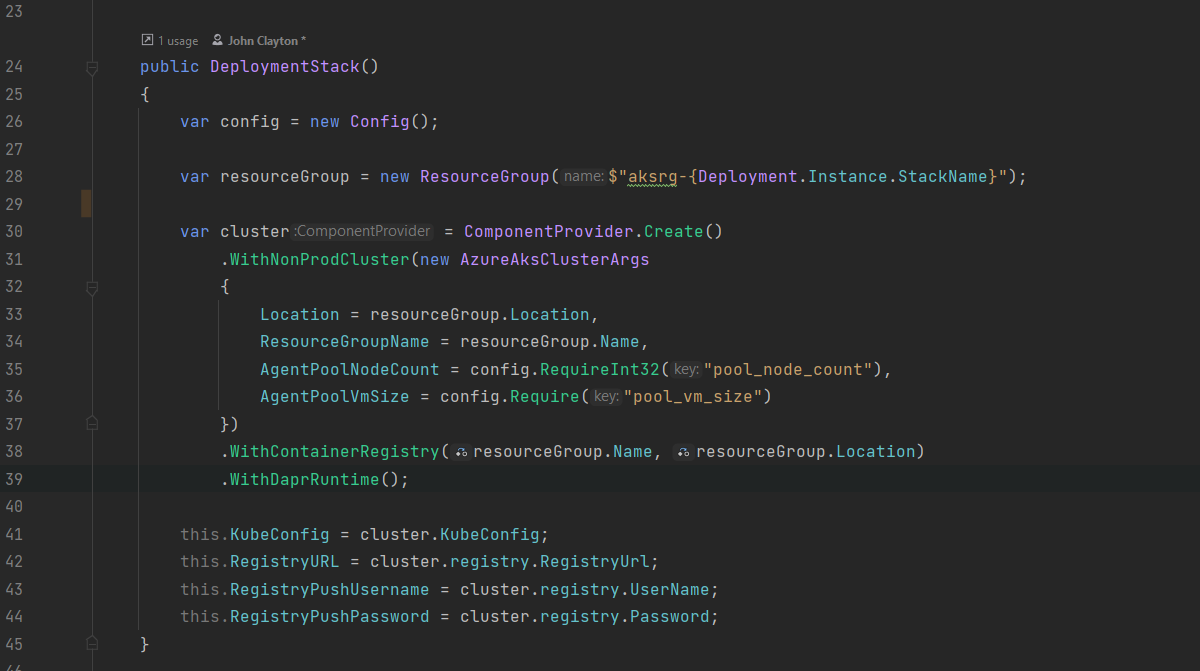
I quickly reached the point where I could express the desire to have an AKS cluster with an attached container registry, along with service principals that were allowed to push into the registry…
In just a few lines of code.
Let’s look again at the post’s header image - those few lines of code deploy a simple AKS cluster, an Azure Container Registry as well as the service principals. The AKS cluster “kubeconfig” value along with the Container Registry URL and user/password are exposed securely via the stack configuration; making re-use easy from anywhere else - code or command line.

The last stage was to add the “application layer”.
For this I decided to create another Pulumi project, and then I added docker build, registry push and dapr-traffic-control application (via a Helm Release) to the project.
This was fun! Now I had:
- A basic infrastructure layer (Pulumi Project)
- An application layer (Pulumi Project)
- A C# library to help with both (C# Class Library)
- A nice feeling - this was easy to use and refactor (Smile On My Face)
So, what else came out of this experiment?
Pulumi Community
The community hangs out on Slack. I’m not sure how many of the members are Pulumi staff, but it feels like quite a few - questions are answered lightning quick, and the community is very friendly.
Slack is maybe not so awesome for history, as there is a limit to the number of historical posts I can search/view with a free account - but it’s a great way to learn from others. Sign up and get involved.
Native Provider
Native Provider? What?
All IaC tools drive infrastructure changes via the underlying cloud or provider API. In Azure, that’s the Azure Resource Manager - ARM for short.
Cloud systems and anything else you want to manage via IaC have these underlying API layers to help manage and control them.
Your IaC tool of choice always needs to turn the desired state model into API calls against the underlying provider API - and Pulumi is no different in this regard.
Where Pulumi differs is how the SDK is created. Pulumi generate the Azure Provider SDK from the underlying provider’s API specification. In the case of Azure this means they are using the OpenAPI spec of the ARM to generate the Pulumi C# SDK.
Lots of words - what does that mean?
It’s HUGE - it means you get Day 0 support for Azure (and the other providers they do this for):
- Day 0 support - no more waiting for providers to be updated
- Terminology is consistent - the keywords used to control components are the same keywords that ARM is expressing; which will be the same as what Microsoft will use in their documentation - talk about leverage!
- Lots of SDK updates - I must have updated mine 3 times within a 2 week period
- You can make use of Azure Preview features - Azure Preview features are not supported by the Azure SDKs, but they are supported by the Azure Resource Manager
Pulumi Service
The Pulumi Service knocks two problems on the head instantly; encryption and state management. All the secrets are stored encrypted by a per-stack specific key. State management comes out of the box, by default.
The service can scale up to provide a team with RBAC as well as deployment of IaC policies - I’ve not covered those topics here - the short version is: “you can force deployments to fail if your policy code detects a problem”.
Even if the business model is a little strange to start with (management of resources cost per hour) - the upside is clear; and if the cost really is a show stopper for you - you can set up your own back end store, just like you learned to do using Terraform.
Food for thought
It’s not all roses (it never is).
I encountered a few issues, which by the time you read this might be resolved - here are some of the things I encountered during the deep dive or have thought about since:
- I built a two project system, one project for the cluster (base infrastructure) and another for the apps on top of that. If I destroy the infrastructure project before the app project, then the app project state gets a bit confused because it cannot find any resources. This makes sense, given I just deleted the entire AKS cluster
- When state goes wrong Pulumi naturally stops working. Pulumi CLI offers tools to export and re-import state. The state did get broken once for me, and I repaired it - albeit with a bit of trepidation by using the
export/importcommands of the Pulumi CLI. That this possibility exists is really good, and I guess will be useful for production environments - Pulumi is a small company, the product is relatively new.
- The Pulumi Service pricing could change (just like any company)
- If the Pulumi Service goes down - my CI/CD pipeline will fail. On my TODO list is to read their SLA and compare it to that of a storage back end such as Azure Blob Storage. Compared to my use of Terraform to date which makes use of Azure Blob Storage, this is a risk worth more investigation
Advantages
I’m only 1 week in, and already the following is clear:
- Use of general purpose languages that are already popular - Javascript, Typescript, Go, Python, C#. This massively reduces the on-boarding cost, because people consider these language a known quantity. Resistance to change is a powerful force and therefore anything that lowers the barriers to change is going to help adoption
- Bring your own tools - as Pulumi employs common programming languages, all of your tooling comes for the ride. Less learning, means less barrier to entry - and more adoption
- Refactoring / decomposition - it’s so so easy, it “just works”. I wrote most of my IaC proof of concept using Rider - meaning I get all the benefits of that as well, since it’s just plain ‘ol C# in my case
- I can create version controlled libraries for my infrastructure, publish them as NuGet packages and re-use them in various projects. This is also a great way to share learning experiences across an organisation
- Multiple tool chains expressed in a single place. I used Kubernetes, docker build + push and helm - and through all of that I was able to express my dev, build and deploy process clearly and cleanly within Pulumi. This makes it realistic to create a “single pane of truth” for deployment knowledge
- Environment configuration is easy. Pulumi stacks make it possible to try experiment / iterate quickly
- Pulumi Native Provider - never again will I need to wait for the Terraform provider to be upgraded! Not that Pulumi is bug free, but this is a huge step forward in terms of the tooling
- While it’s not “Hit F5 to Debug” simple, debugging infrastructure deployment is possible - thanks Sam Cogan for the tip
- Community - I had several questions on the Slack channel that got answers within hours, sometimes less
Future
I predict that the real-code as infrastructure movement will take over the other types of IaC. If you know Terraform, keep an eye on their Cloud Development Kit - as of April 2022, the CDKTF is still beta and not supported in production - but it looks promising.
CDKTF is under active development; we’re still working out key workflows and best practices. We’re iterating fast and are likely to introduce breaking changes to existing APIs to improve the overall user experience of the product. Like other HashiCorp pre-1.0 tools, some early-adopter users are already using CDK for Terraform in production, and we are working with those users to validate and improve workflows.
Early adopters of CDKTF should expect to encounter and work around bugs occasionally, may need to refactor their codebase with each major release, and will intermittently need to use HCL and understand how JSON Terraform configurations are generated. For example, overrides may be required to use Terraform functionality that cannot currently be expressed using CDKTF. Our goal is to provide a user experience where this is an exceptional edge case. If you’re comfortable with this level of troubleshooting, we’re very interested in your feedback and practical experience. The Community page explains how to ask questions, submit issues, and contribute to the project.
Final thoughts
Using Pulumi I noticed that the infrastructure topics start to become part of an integrated developer experience.
I can wrap complexity, integrate cloud provisioning, use docker build / push, use RBAC and per-environment configuration - all in a single system, and I’m only 1 week into this experiment!
Pulumi is wonderfully powerful and gives us a framework that can help us share our progress quickly and seamlessly with other developers.
I’m in.
That’s a wrap
I’d like to give my thanks to the Pulumi Community members that spent time to review my article and provide lots of useful suggestions for improvements.
Feel free to comment below or get in touch with me directly at info@effective-flow.ch , if there is something else you’d like to know - post below and I’ll try to expand on what is already here.
Happy coding!